Handwriting to Markdowns using GPT-4o (Second Brain)
Although I prefer taking physical notes during meetings, digitizing them can be a time-consuming process. In 2022, I created an Azure Logic App that uses Azure AI Vision to improve my productivity. However, fixing OCR issues was counterproductive and outweighed the benefits of automation. With the release of GPT-4V and GPT-4o, I became curious whether GenAI could address:
- poor handwriting and spelling errors,
- grouping of notes into various sections (boxed notes, columns, line dividers, etc.),
- recognize whiteboard images that include handwriting and sticky notes, and
- recognize non-handwritten use cases like screenshots, brochures, and other OCR-candidate images.
This is what this post is about.
Solution Flow
While it may be tempting to create a super prompt that can perform multiple actions with a single call, I found that this type of prompt is extremely challenging to write and almost impossible to debug (see my previous attempt here).
To keep things simple, I opted to use consumption-tier cloud-native services for this implementation. This includes Azure Logic Apps to monitor my OneDrive folder, which allows me to snap photos using the OneDrive mobile app and save them directly to the folder. Additionally, I used Azure Functions (Python) which is triggered by the Logic App to further process the images.
The Azure Function is where I make a series of completion calls to Azure OpenAI GPT-4o. The flow of the process looks like this:
flowchart LR
H[Handwritten Notes/Image<br />from OneDrive] --> |image content| N{Detect Note Type}
subgraph "Azure Function"
subgraph "Azure OpenAI GPT-4o Prompts"
N --> |Paper| P[Paper System Prompt]
N --> |Whiteboard| W[Whiteboard System Prompt]
N --> |Other| O[Generic System Prompt]
P --> PR[Proof Read]
W --> |text output| PR
O --> PR
PR --> S[Section<br />Headers]
end
S --> IT[Initial<br />Output]
IT --> |add<br />metadata| Output[Final<br />Output]
end
Output --> |save| MD[Markdown File<br />in OneDrive]
To keep this post brief, I won’t be sharing all of my prompts and source code. However, you can view the source code in this repo. The repo includes the prompts, Azure Function code, and the Azure Logic Apps ARM deployment template. Additionally, I’ve included my implementation notes in the README file.
My writing style differs when using a notebook versus a whiteboard. When taking notes in a notebook, I typically write from the top line to the bottom, with occasional exceptions such as small “note sections” on the right, small tables, or diagrams.
However, when using a whiteboard, I tend to jot down different thoughts in various corners of the board, depending on where there’s available space. Additionally, whiteboards are often used in group settings where other people may be contributing or writing on a different topic in a separate area. Whiteboards can also be more sophisticated, with the inclusion of sticky notes or printouts pasted on the board. Digital whiteboards, such as Microsoft Whiteboard, Klaxoon, Mural, and Miro, offer even more flexibility and options for content creation on the board.
To simplify the system prompt implementation, I executed completions in stages. First, I used a vision model to determine the type of image and then used a different prompt for each image type.
Paper OCR
This is a sample output if the note type is PAPER:
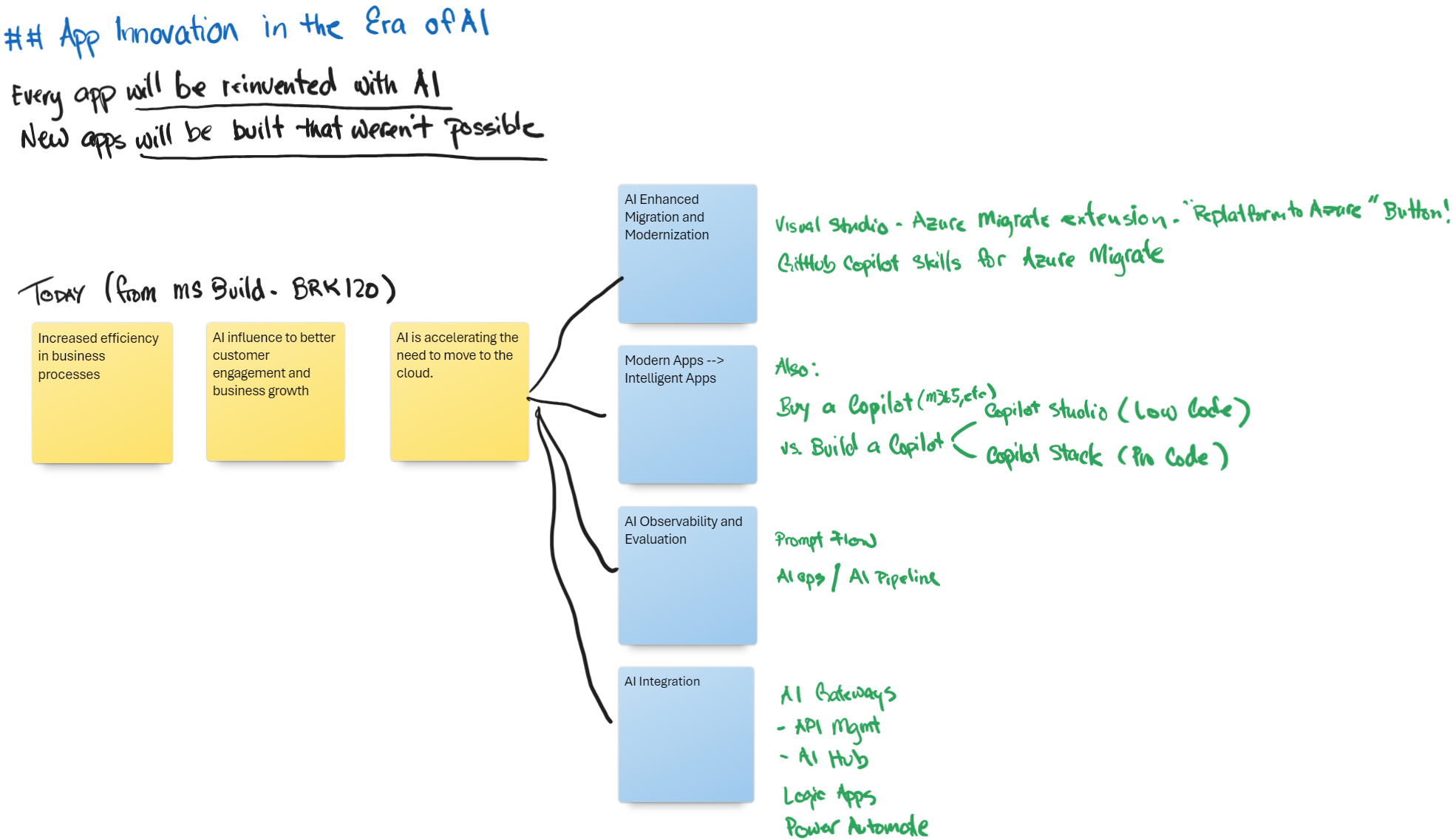
 GPT-4o output for Sample Paper Notes (see prompt here)
GPT-4o output for Sample Paper Notes (see prompt here)
Whiteboard OCR
This is a sample output if the note type is WHITEBOARD:

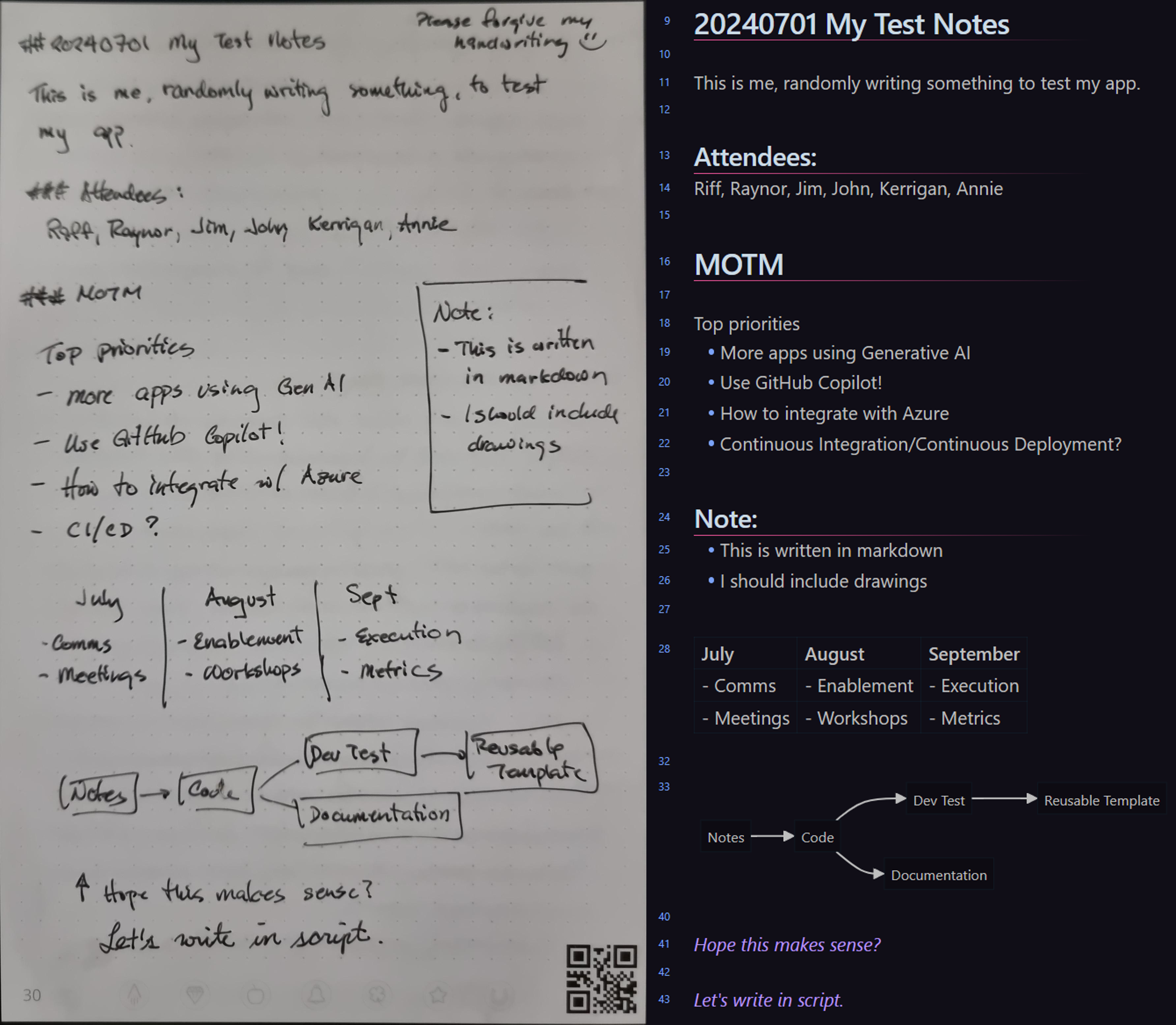
 GPT-4o output for Sample Paper Notes (see prompt here)
GPT-4o output for Sample Paper Notes (see prompt here)
Post-Processing
To post-process the output, I used a combination of text completions and Python code. Since not every section in the notes may be correctly labeled, I utilized a text completion prompt to understand the content of sections that contained a {PLACEHOLDER_HEADER} and then generate a suitable header (see prompt here).
Furthermore, I used Python code to further refine the output. At times, the output would include unnecessary block quotes, so I used Python to remove them.
1
2
3
```markdown
Text extraction enclosed in markdown block quotes.
```
Although I attempted to resolve this issue by improving the system prompts, it did not work. However, a simple Python method (generated by GitHub Copilot) was able to fix it.
1
2
3
4
5
6
7
8
9
10
# A function that takes a text as input and removes possible ```markdown``` code blocks
# for example, if the text is "```markdown\n# Title\n```", it will return "# Title"
# or if the text is "```markdown # Title ```", it will return "# Title"
def remove_markdown_code_blocks(text: str) -> str:
text = text.strip()
if text.startswith("```markdown") and text.endswith("```"):
text = text[len("```markdown"):]
text = text[:-len("```")]
return text.strip()
Next Steps
Since I plan to use this automation on a daily basis, I intend to further enhance it. You can find the current state of the code and the enhancements I have in mind on this GitHub repository.
I hope you enjoyed reading this post. If you have any suggestions, please feel free to share them in the comments below or in the discussions section of the GitHub repository.