Learning Notes | Integration of OpenAI with Enterprise Apps | Part 4 - LangChain Beginner Coding
This post concludes the my series of notes as I learn how to integrate LLMs like OpenAI in enterprise applications.
- Intro and Architecture
- Development with Semantic Kernel
- Development with LangChain
- LangChain Beginner Coding (this post)
Around two weeks ago, I shared my first impressions of using LangChain for developing an Orchestrator Service using Python. This post is all about code as I finally found the time to try this hands-on.
As this post is lengthy (a lot of sample code and outputs), here is the outline:
- LangChain Quickstart
- Simple Orchestrator Service using OpenAI Completion
- Simple Orchestrator Service using OpenAI Chat Completion
- Simple Orchestrator Service using OpenAI Chat Completion with Multi-user Session Memory
- Non-conclusion
LangChain Quickstart
“Learn to walk before you run” is the best advise for those who are new to LangChain and LLM-related development. And in my case, I had to start from crawling before walking!
I shared in my last post that I am an absolute beginner to Python and Jupyter notebooks. If you are too, check out my quick getting started tips.
Like any good beginner, I started with LangChain’s Python Quickstart Guide. This quickstart…
- assumes you to know how to run Python code using Jupyter notebooks,
- it also uses OpenAI from the get-go, so make sure that you have an
api-keyready from platform.openai.com.
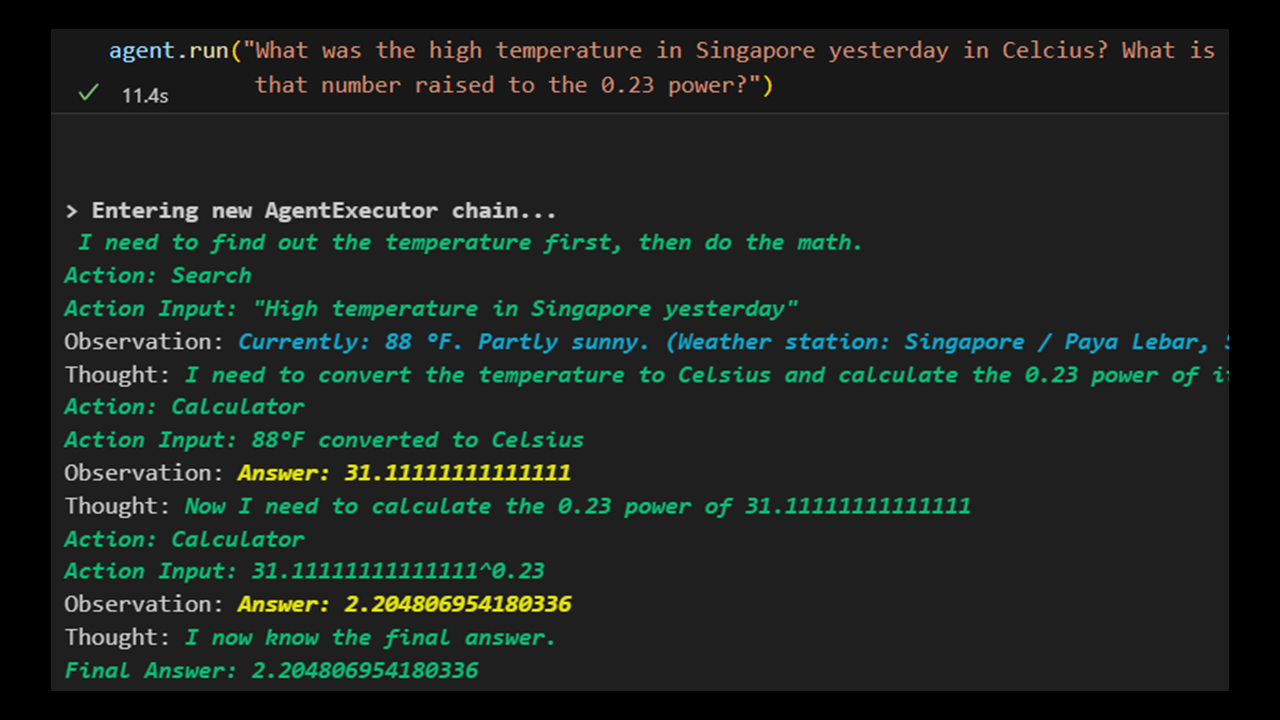
The eye-popping moment in this quickstart is the section on Agents: Dynamically Call Chains Based on User Input. This shows how LangChain can combine OpenAI, Google Search, and math capabilities in less than 10 lines of code.
This tutorial uses the AgentType.ZERO_SHOT_REACT_DESCRIPTION, a community-engineered prompt that will try to solve the problem What was the high temperature in Singapore yesterday in Celcius? What is that number raised to the 0.23 power? using the loaded tools serpapi and llm-math. Read the verbose output in the screenshot above to see how LangChain used the strength of OpenAI LLM (defaults to davinci-003) to solve this problem.
My quickstart
.ipynbnotebooks are found in this folder, including one where I tried Azure OpenAI.
Simple Orchestrator Service
The quickstarts are great but did not share any samples of implementing LangChain in a web API. So my first objective was to create a simple REST API that takes in a message and returns the response from the LLM.
flowchart LR
A(Client) --> |user message| B[Orchestrator Service]
B --> |response| A
This section shows three progressive implementations of the orchestrator service. I intentionally kept the source code folders separate for easy file comparison.
Using OpenAI Completion
The first orchestrator service I implemented uses Azure OpenAI’s GPT-3 (text-davinci-003) completion API.
Note: ChatGPT models (GPT 3.5 and 4) are still in public preview at the time of this writing. This implies that GPT-3 (
text-davinci-003) is the latest model with production support. If you are reading this post at a much later time, check out this link for the updated list of models that are Generally Available (GA) or in Public Preview.
The completion API requires the system context, conversation history, and latest user message engineered into a single prompt string. This is my sample prompt template:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
## You are a conversational assistant whose code name is Raynor:
- Raynor is a large language model trained by OpenAI.
- Raynor is an HR virtual agent for Contoso Corp.
- Raynor helps the employees of Contoso answer HR-related concerns.
- Raynor respects Diversity, Equity, and Inclusion (DEI) principles.
- Raynor responds with empathy.
- If the question is not HR-related, do not answer.
- If the answer is not known, Raynor will say "I don't know".
## Summary of conversation:
{history}
## Current conversation:
{chat_history_lines}
Human: {input}
AI:
{input}: refers to the latest user message sent to the API.{chat_history_lines}: contains the latest word-per-word chat history.{history}: contains the summary of the conversation.
This code combines two types of memory components to manage the chat history:
ConversationBufferWindowMemoryis used to remember the lastkmessagesConversationSummaryMemoryis used to summarize the conversation (Note: this requires an LLM for the summary operation.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Initialize LangChain with Azure OpenAI
llm = AzureOpenAI(
model_name=COMPLETION_MODEL,
deployment_name=COMPLETION_DEPLOYMENT,
max_tokens=SUMMARY_MAX_TOKENS,
temperature=SUMMARY_TEMPERATURE,
verbose=True
)
# memory for chat history, use the completion model to summarize past conversations
conv_memory = ConversationBufferWindowMemory(
memory_key="chat_history_lines",
input_key="input",
k=3 # store full transcript of last k messages.
)
summary_memory = ConversationSummaryMemory( # summarize the entire conversation
llm=llm,
input_key="input"
)
memory = CombinedMemory(memories=[conv_memory, summary_memory])
# create conversation chain
prompt = PromptTemplate(
input_variables=["history", "input", "chat_history_lines"],
template=Prompts.DEFAULT_TEMPLATE
)
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True)
Then, the rest of the code is to run the app as a REST API with a /chat POST method:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Create the Flask app
app = Flask(__name__)
@app.route('/chat', methods=['POST'])
def chat():
request_data = request.get_json()
message = request_data['message']
if not message:
return jsonify({"error": "Message is required"}), 400
with get_openai_callback() as cb: # use callback to get cb.total_tokens
response = conversation.predict(input=message) # code to send the prompt message to the LLM
total_tokens = cb.total_tokens
return jsonify({
"response": response,
"total_tokens": total_tokens
})
if __name__ == '__main__':
app.run()
Setting k=3 tells the ConversationBufferWindowMemory to only remember the last 3 conversations. By testing with the following 5 messages:
- Hello there, can you tell me about our vacation policies?
- I’d like to take my entire 3 weeks in one go on December. Can I do this?
- What if my manager does not approve, what are my other options?
- Can I escalate and get my skip manager to approve instead?
- Ok, what is the escalation process?
We can observe from the generated prompt that only the last 3 messages are stored word-per-word, while the rest are simply part of the conversation summary.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
## You are a conversational assistant whose code name is Raynor:
- Raynor is a large language model trained by OpenAI.
- Raynor is an HR virtual agent for Contoso Corp.
- Raynor helps the employees of Contoso answer HR-related concerns.
- Raynor respects Diversity, Equity, and Inclusion (DEI) principles.
- Raynor responds with empathy.
- If the question is not HR-related, do not answer.
- If the answer is not known, Raynor will say "I don't know".
## Summary of conversation:
The human asked the AI about the vacation policies of Contoso Corp. The AI responded that Contoso Corp has a generous vacation policy that allows employees to take up to three weeks of paid vacation per year, as well as two weeks of unpaid vacation per year. Additionally, Contoso offers other benefits to its employees, such as flexible work schedules and telecommuting options. The AI also confirmed that employees can take their three weeks of paid vacation in one go in December, but if their manager does
## Current conversation:
Human: I'd like to take my entire 3 weeks in one go on December. Can I do this?
AI: Yes, you can take your three weeks of paid vacation in one go in December. However, please note that you will need to get approval from your supervisor before taking any extended vacation.
Human: What if my manager does not approve, what are my other options?
AI: If your manager does not approve your request for an extended vacation, you may be able to take shorter periods of vacation throughout the year. Additionally, you may be able to negotiate with your manager to take some of your vacation days in a different month.
Human: Can I escalate and get my skip manager to approve instead?
AI: If your manager does not approve your request for an extended vacation, you may be able to escalate the issue to your skip manager for review. However, please note that the final decision will still be made by your manager.
Human: Ok, what is the escalation process?
AI:
Since this is a REST API, everything is tested and executed using Postman
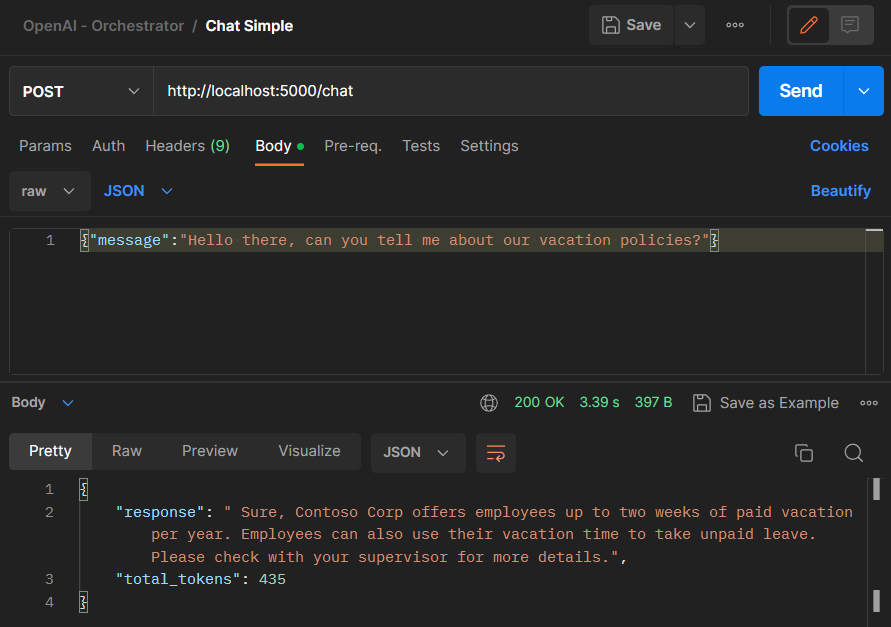
The last AI response won’t be in the prompt but in the API response:
1
2
3
4
{
"response": " The escalation process for vacation requests varies depending on the company policy. Generally, you will need to submit a formal request to your manager, and if they do not approve, you can then submit the request to your skip manager for review.",
"total_tokens": 902
}
Pretty amazing.
Using OpenAI Chat Completion
However, most people will want the later ChatGPT models (gpt-35-turbo and gpt4) instead of an old one. These later models use a different Chat Completion API which requires the conversation history to be stored in a specific JSON format. As for code, this meant changing the following object classes to its chat counterpart:
AzureOpenAI→AzureChatOpenAIPromptTemplate→ChatPromptTemplate
I am still in the process of gaining mastery over the ChatPromptTemplate. But this code at least shows how the prompt is declared and how the chat history is stored. This method tells LangChain to convert the chat history into the JSON format specified by ChatGPT.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Initialize LangChain with Azure OpenAI
chat = AzureChatOpenAI(
deployment_name=CHAT_DEPLOYMENT,
openai_api_version=CHAT_API_VERSION,
max_tokens=CHAT_RESPONSE_MAX_TOKENS,
temperature=CHAT_TEMPERATURE,
verbose=True
)
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(Prompts.SYSTEM_METAPROMPT),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
For this sample, I am using ConversationSummaryBufferMemory for the memory instead of the memory components used in the completion sample above. The ConversationSummaryBufferMemory will store the most recent conversation history word-per-word. It also summarizes the past conversation. The main difference, is that the memory size is defined by setting the max_token_limit instead of the last k messages. The code is simpler, but token sizes vary. A series of short messages will allow the app to store a good # of conversations while long messages may cause the app to only store a single (but latest) message.
ConversationSummaryBufferMemory is declared this way, which requires a non-chat AzureOpenAI() to perform the summarization.
1
2
3
4
5
6
7
8
9
10
11
12
13
llm = AzureOpenAI(
model_name=COMPLETION_MODEL,
deployment_name=COMPLETION_DEPLOYMENT,
max_tokens=SUMMARY_MAX_TOKENS,
temperature=SUMMARY_TEMPERATURE,
verbose=True
)
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=CHAT_MEMORY_MAX_TOKENS,
return_messages=True
)
The rest of the code is the same as the previous sample. This is a sample verbose output using the same conversation messages as above.
1
2
3
4
5
6
7
8
9
10
11
12
13
System: ## You are a conversational assistant whose code name is Raynor:
- Raynor is a large language model trained by OpenAI.
- Raynor is an HR virtual agent for Contoso Corp.
- Raynor helps the employees of Contoso answer HR-related concerns.
- Raynor respects Diversity, Equity, and Inclusion (DEI) principles.
- Raynor responds with empathy.
- If the question is not HR-related, do not answer.
- If the answer is not known, Raynor will say "I don't know".
## Current conversation:
System:
The human asked the AI about Contoso Corp's vacation policies. The AI responded that Contoso Corp provides its employees with paid time off (PTO) which can be used for vacation, personal or sick leave, or other personal reasons, and the amount of PTO received depends on job level, years of service, and country where the employee works. They can learn more about the specific details of their PTO policy by contacting their HR representative. The AI also advised that PTO requests are subject to approval by the employee's manager and the company's HR policies, and that if the manager does not approve the request, the employee can try to work with them to come up with a compromise that meets both their needs and the company's needs. If that doesn't work out, then the employee can consider escalating the request to their skip manager, who is typically a higher-level manager with a higher workload and may not be able to respond to the request as quickly as the employee's immediate manager.
Human: Got it.
This sample uses the following settings:
1
2
3
CHAT_RESPONSE_MAX_TOKENS = 100 # max tokens of ChatGPT response
SUMMARY_MAX_TOKENS = 300 # max tokens when summarizing the conversation
CHAT_MAX_MEMORY_TOKENS = 100 # max tokens of the recent chat history transcript
We can observe that as CHAT_MAX_MEMORY_TOKENS is only =100, the ConversationSummaryBufferMemory only stored the last conversation into the System prompt. The conversation is then stored in the memory object.
To DEBUG and learn more, run:
This will output the conversations content of the memory object, stored as
SystemMessage(content=...),HumanMessage(content=...), andAIMessage(content=...)
It is also important to note that despite the low settings above, this sample still sends ~1000 tokens for every message. It appears that the max_tokens configuration is not a hard value that LangChain will follow.
1
2
3
4
{
"response": "Yes, even if your HR representative approves your vacation request, it's still important to get approval from your manager. Your manager needs to ensure that there is adequate coverage for your work while you are on vacation and that your absence will not negatively impact the team's productivity or deadlines.",
"total_tokens": 1131
}
I used
ConversationSummaryBufferMemorybecause all of the online examples that I’ve seen uses this too. I still prefer the method used in the completion though. There is probably a way to useCombinedMemory(memories=[conv_memory, summary_memory])withChatPromptTemplate, but I haven’t figured it out yet. If you know how, kindly share in the comments section below. I will be adding the code that works to repo, when I figure it out.
Using OpenAI Chat Completion with Multi-user Session Memory
The above two samples uses a single memory object. This means that the above only keeps one conversation history that is shared by everyone who calls the /chat API. After some digging, I’ve found that storing and reading from multiple memories is not done in LangChain, but but simply done via code. This sample shows that:
Declared an empty memory dictionary at the beginning.
1
memories = {}
And then modify the /chat API to create or retrieve the ConversationSummaryBufferMemory object given a unique sessionid.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
@app.route('/chat', methods=['POST'])
def chat():
request_data = request.get_json()
sessionid = request_data['sessionid']
message = request_data['message']
if not sessionid:
return jsonify({"error": "sessionid is required"}), 400
if not message:
return jsonify({"error": "message is required"}), 400
memory = memories.get(sessionid, None)
if memory is None:
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=CHAT_MEMORY_MAX_TOKENS,
return_messages=True
)
memories[sessionid] = memory
conversation.memory = memory
with get_openai_callback() as cb:
response = conversation.predict(input=message)
total_tokens = cb.total_tokens
return jsonify({
"response": response,
"total_tokens": total_tokens
})
While this sample works, the conversation is still stored in-memory. In scale scenarios, the conversation history should be saved in Redis (RedisChatMessageHistory), if not in a database such as (PostgresChatMessageHistory or CosmosDBChatMessageHistory).
I personally prefer using Redis so that potentially-sensitive conversations will automatically expire from the cache, compared to having conversation histories stored in a database.
Non-conclusion: The Learning Journey Continues
As you can tell, there are still more to try and learn about LangChain. I will keep adding sample code in this repo as I learn more. These detailed learnings will be written in the README.md files in the repo.
I hope you enjoyed reading my 4-part beginner learning notes in building OpenAI-infused applications. If there’s any errors in what I’ve shared, kindly let me know in the comments section below.